Validation of community IDs on iNaturalist
(Wondering how to add your blog posts to this blog? Have a look here: Get involved)
Short introduction to the feature
iNaturalist is a an online platform where anyone can share and identify observations of wild animals and plants. When users upload an observation, they can give a guess on the species observed, also called “taxon”. Since not all users are biodiversity professionals, this guess can be more (e.g. “Seven-sptted ladybird”) or less (e.g. “insect”) precise. It might also be wrong. To get a Taxon identification with an accuracy that is safe to use in a research database, iNaturalist has developed a standardized community validation procedure.
How does it work?
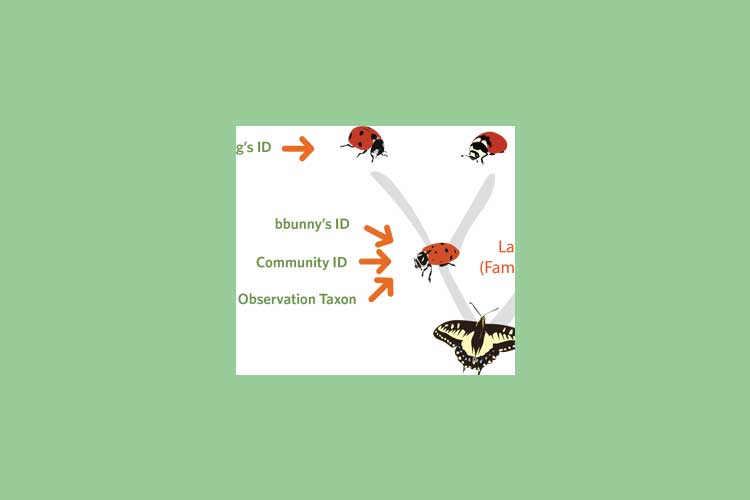
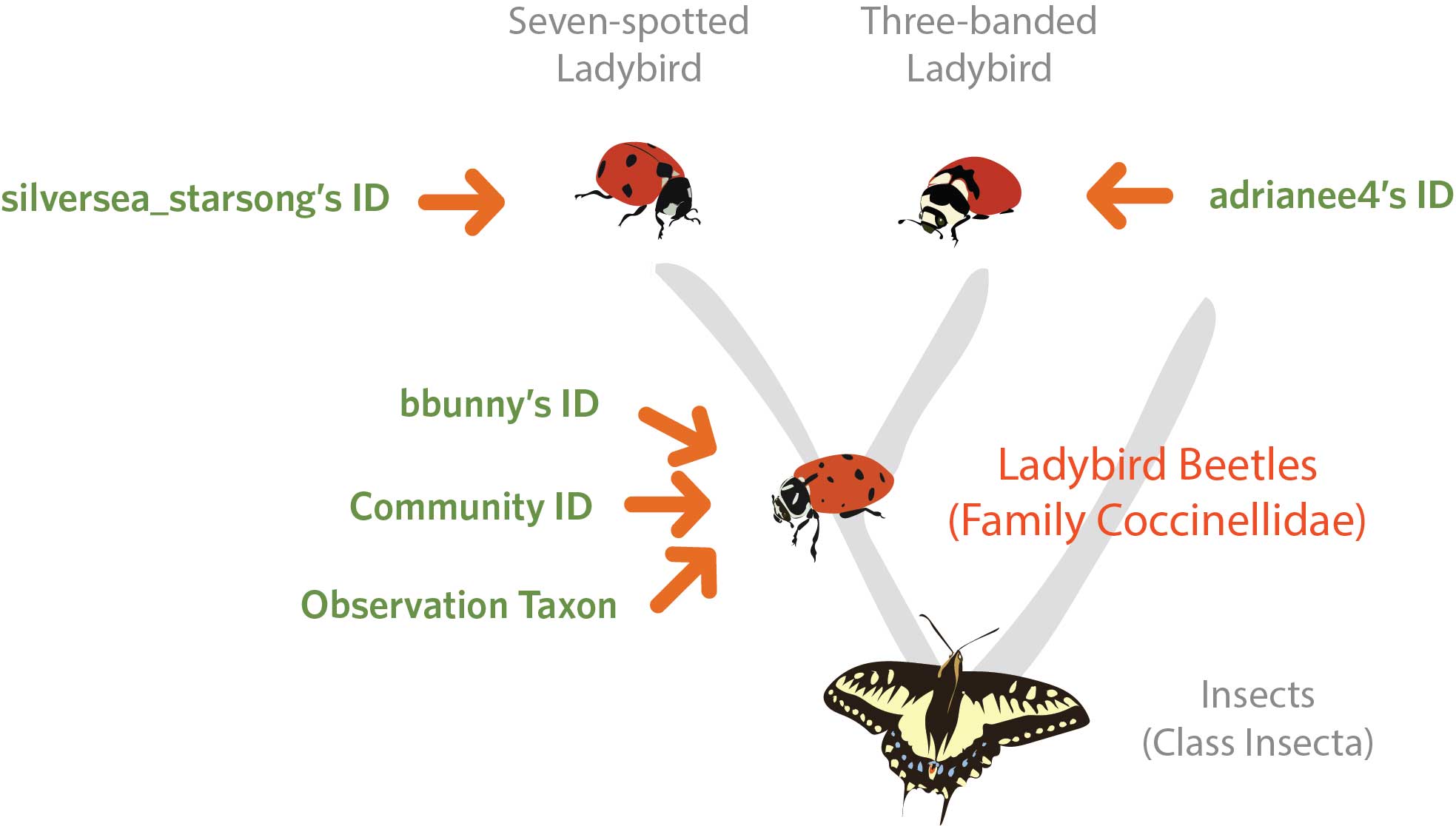
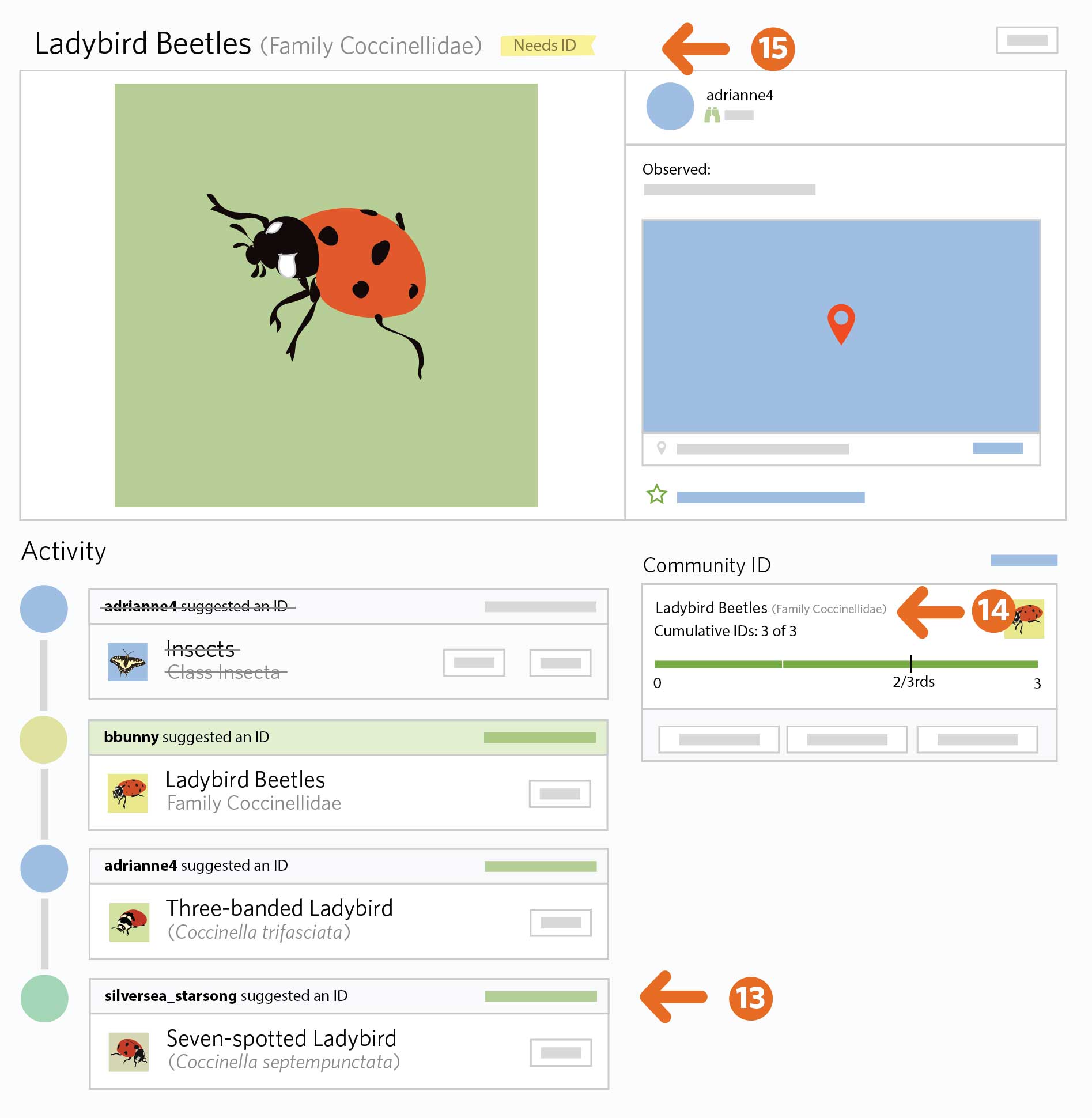
When a user uploads an observation, it is labelled “needs ID”. They are asked to give a guess on the taxon(the “observation taxon”) Other users that visit the Identify site of iNaturalist can find the new observation there. By looking at the photo and/or other metadata, they can give a guess on the taxon, with any classification precision they feel comfortable with, agreeing to or disagreeing with the observation taxon.
Once at least three users gave a guess on the taxon, and if at least 2/3 of them agreed on a taxon, the observation gets labelled as “research grade”. The taxon with the highest precision that 2/3 users agreed on becomes the “community ID”. This idea can change over time: At any time, other users can agree or disagree with the identification.
Figures 1 and 2 illustrate this process on the example of a ladybird.
The whole process with many helpful visualizations is explained here, under the tab “Identifying observations”: Getting started | iNaturalist.org
Thoughts
This solution of iNaturalist to leverage the wisdom of the crowd to collectively identify an observation, allowing different levels of precision, is a great example for a communal validation process. This exact procedure is of course specifically for biodiversity data (making use of the taxonomy hierarchy, and having a limited set of possible answers, because there is a limited number of species). However, I think a similar approach - tagging new entries with “needs validation”, having users make guesses, and accepting the answer a certain proportion of users agreed on - is imaginable for other problems. The accuracy of iNaturalist community IDs has been considered excellent in a study on termite classifications (Hochmair et al., 2020), which is another argument for the effectiveness of this communal validation process.
Another strength of this approach is its openness. It is publicly visible which identification users suggested, so it is traceable how the community ID was determined. In this way, users can get feedback on their responses and, thus, an opportunity to learn. With regards to transparency and user empowerment, this can be seen as an advantage over more traditional crowdsourcing approaches as used in Mechanical Turk or Zooniverse, where the communal validation part is not visible to users.
References
- iNaturalist website
- Getting started guide on iNaturalist with a detailed explanation of the communal validation process
- Hochmair, H. H., Scheffrahn, R. H., Basille, M., & Boone, M. (2020). Evaluating the data quality of iNaturalist termite records. PloS one, 15(5), e0226534. (URL)
(updated 15-03-2021 by Katharina/@katoss)